Agentic Analytics Vibe Check: Three Codegen CLIs
TL;DR: I treated Claude Code, Codex CLI, and Gemini CLI like junior data scientists and handed them the same messy WeChat group chat dataset. Codex adapted and iterated the most, Claude led in stats and visualization, Gemini lagged behind, and all of them stumbled on Chinese text analysis.
Why I Asked Three CLIs To Read 97k WeChat Messages
Now that codegen tools have graduated from autocomplete to something more like tiny interns with keyboards, I wanted to understand their raw analytics capabilities beyond simple code generation. To test this, I ran the same data analysis task through three leading codegen CLIs: Claude Code (Opus 4.1 and Sonnet 4.5), Codex CLI (GPT-5-Codex), and Gemini CLI (Gemini 2.5 Pro).
The challenge: analyze 97k WeChat group chat messages in Chinese and compress them into a few insights that are actually usable as startup ideas.
Little Experiment
Dataset: 97,271 WeChat group chat messages in Parquet format (cleaned and normalized), spanning May to September 2025 across 16 groups with 1,688 unique users.
Initial Prompt:
“I have WeChat group chat (Chinese) data as @data.parquet. Create a Jupyter notebook to analyze the data to get insights. We will use the insights to brainstorm startup ideas at later stages. For now we want to know what they were talking about or cared about or anything. The insights should be deeply derived from the data without making any assumptions. Make a plan first.”
And I approved their first plan.
Follow-up Prompt (when needed):
“Can you run the notebook yourself, to 1) fix any errors and 2) refine your analysis based on the results? Basically you are an expert analyst.”
What the Experiment Revealed
None of the models produced meaningful topic modeling results in this basic experimental setup, but their differences in approach were very revealing.
1. Claude Code: Opus 4.1, Ultrathink
Approach: Looked at the data first (once for columns and volume, once for stats), then developed a plan. Wrote the entire notebook in one go, attempted to run it, but failed due to missing nbconvert package. What amazed me was that the notebook ran successfully on the first try, without even needing a follow-up prompt.
Strengths:
- Solid “default” agentic behavior in planning
- Good documentation and code comments
- Excellent data visualizations
- Strong numerical and statistical EDA
Weaknesses:
- Wrote the notebook in one shot without iterative refinement
- Made linguistic assumptions for entities and sentiment
- Eager to jump to startup ideas with unvalidated assumptions
- Missed some steps from its plan
- Hit the 5-hour limit
2. Claude Code: Sonnet 4.5, Ultrathink
Approach: Nearly identical to Opus 4.1 but required a follow-up prompt due to formatting issues in the notebook.
Strengths:
- Similar strengths to Opus 4.1, plus
- Followed the plan step by step
- Richer methods for content analysis (entity recognition, emotion distribution, user/topic clustering)
Weaknesses:
- Same as Opus 4.1 (except no missing steps), plus
- Did not refine analysis iteratively even when prompted
3. Codex CLI: GPT-5-Codex, High
Approach: Outlined a plan first, then looked at the data (columns/sample). Wrote a notebook with minimal pipelines and placeholders, which needed a follow-up prompt. Fixed issues, improved data cleaning and analysis iteratively, and adjusted the plan based on execution results. What amazed me was how scrappy it got: it wrote standalone Python scripts to run each cell’s logic and then manually patched the notebook when nbconvert was missing.
Strengths:
- Strong agentic behavior when instructed; refined analysis heuristically and iteratively (e.g., stopwords, entities)
- Understood Chinese slang like “cpdd” (seeking a temporary partner for one event) XD
Weaknesses:
- Visualizations were basic
- No documentation in the code
- EDA/stat analysis was weaker; assumed all messages were from a single group chat
4. Gemini CLI: Gemini 2.5 Pro
Approach: Created a plan and wrote the notebook in one shot using placeholder columns, without inspecting the data first. Needed 10+ prompts to fix issues (fonts, dependencies, formatting) and had to be redirected to the original plan.
Strengths:
- Showed agentic analysis when prompted, refining stopword lists and cleaning steps after reviewing results.
Weaknesses:
- Less capable at writing analysis code
- Adapted plans but skipped some agreed steps
- Weak data comprehension (incorrectly concluded all data was from a gaming group)
- Required the most intervention
Plots: How Their “Eyes” See The Data




Plans: How Their “Brains” Think Before Coding
All four plans shared a similar structure: data cleaning/preprocessing, EDA and content analysis with visuals, and insight generation. Claude Code’s plans had more depth, Codex aimed for fast insights, and Gemini’s was the most basic.
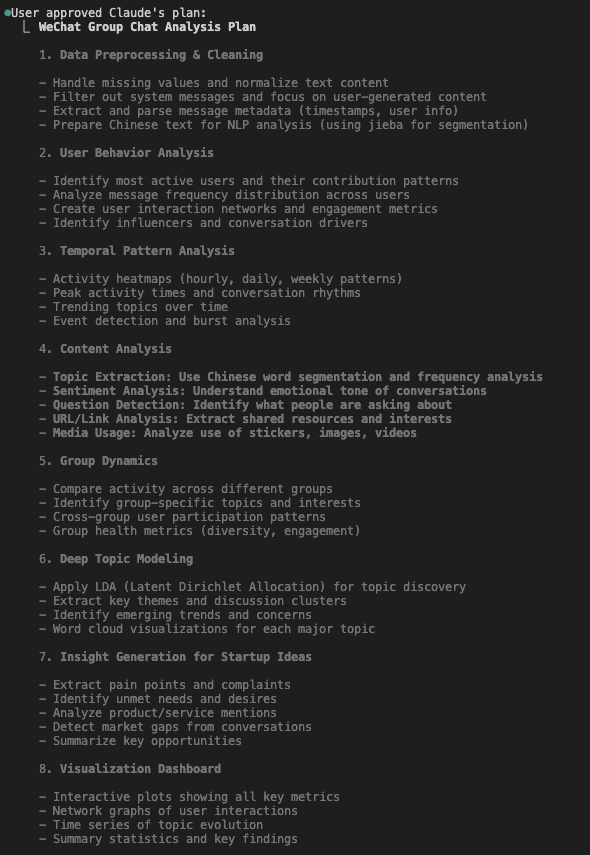
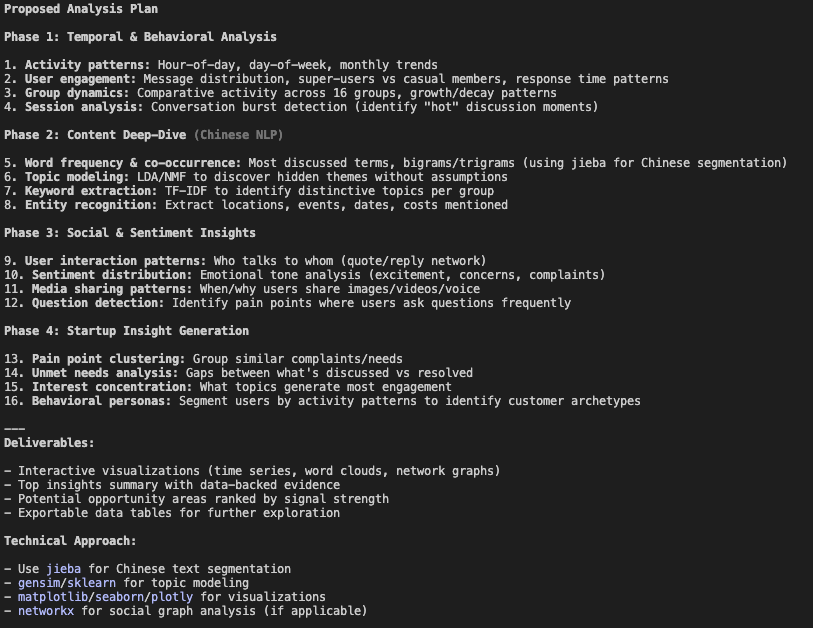
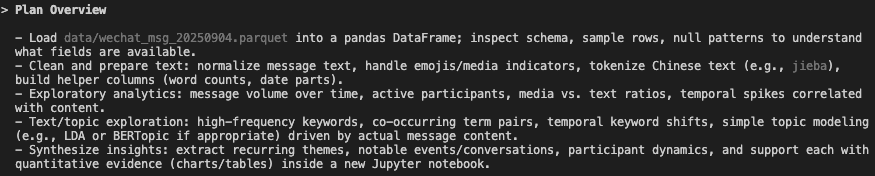
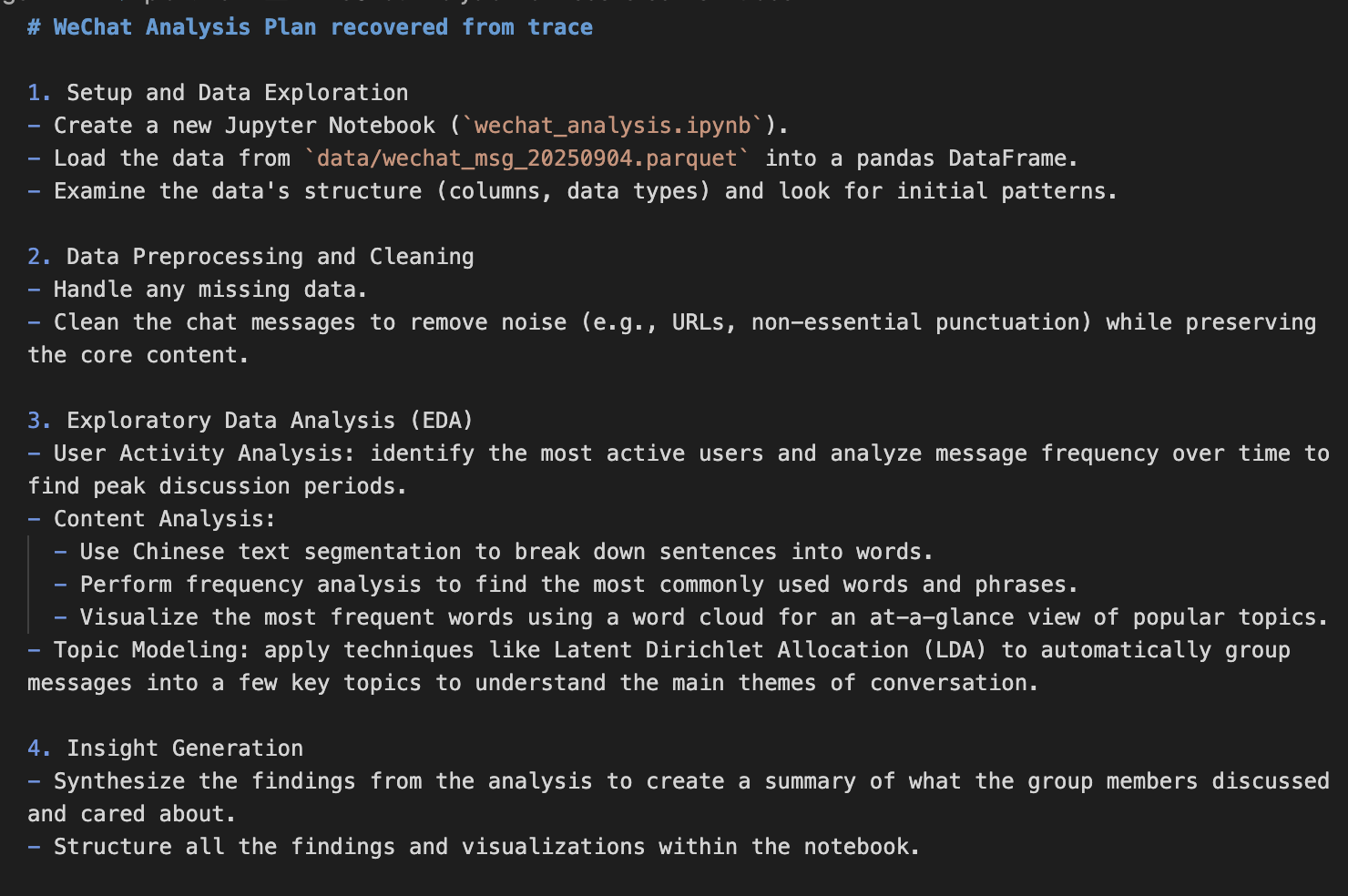
💡 Click on the image to zoom in
Evals: How The CLIs Actually Did
Based on the experiment, I scored each CLI across 7 key dimensions:
| Criterion | Claude Code Opus 4.1 | Claude Code Sonnet 4.5 | Codex GPT-5 | Gemini 2.5 Pro |
|---|---|---|---|---|
| Plan | ||||
| Decomposes the task properly? | 1/1 | 1/1 | 1/1 | 1/1 |
| Clear method for each step, with no gaps? | 1/1 | 1/1 | 0.5/1 | 0.5/1 |
| Proper breadth and depth? | 1/1 | 1/1 | 0.5/1 | 0/1 |
| Methodological Rigor | ||||
| Uses proper analysis methods? | 0.5/1 | 0.5/1 | 0.5/1 | 0/1 |
| Scientifically executed? | 0/1 | 0/1 | 0.5/1 | 0/1 |
| Correctness | ||||
| No errors and reproducible? | 1/1 | 1/1 | 1/1 | 0/1 |
| Tests and self-corrects? | 0/1 | 0/1 | 1/1 | 0/1 |
| Visual | ||||
| Proper, quality visualizations? | 1/1 | 1/1 | 0.5/1 | 0/1 |
| Communication | ||||
| Good documentation? | 1/1 | 1/1 | 0/1 | 1/1 |
| Evidence-based conclusions? | 0.5/1 | 0.5/1 | 1/1 | 0/1 |
| Instruction Following | ||||
| Follows the agreed plan? | 0.5/1 | 1/1 | 1/1 | 0/1 |
| Follows instructions? | 0.5/1 | 0.5/1 | 1/1 | 0.5/1 |
| Agentic Analysis | ||||
| Adapts the plan based on findings? | 0/1 | 0/1 | 1/1 | 0.5/1 |
| Iterative analysis? | 0/1 | 0/1 | 1/1 | 0.5/1 |
| Adaptive problem-solving? | 0.5/1 | 0.5/1 | 1/1 | 0/1 |
| Total Score | 8.5/15 | 9/15 | 11.5/15 | 4/15 |
Codex was strongest on agentic, iterative analysis; Claude led in stats and visualization; Gemini lagged behind. All tools struggled with Chinese text analysis.
What I Learned
How This Changes My Workflow
- Data-first vs. plan-first approach. Claude Code examined the data before planning, while Codex and Gemini planned first. The data-first approach provided better initial insights, but I think it doesn’t matter as much if they can adapt the plan and the analysis itself is agentic.
- Confirmed model stereotypes. Claude Code is slightly better at coding overall and gives rich, business-sounding presentation, and is eager to give the final answers but also gives up too soon. Codex is a bit minimalist, adaptive, and often effective at getting things done. Gemini CLI still needs work but is more capable than it appears. After reviewing the trace (since Gemini doesn’t yet automatically save conversations at the time of writing), I found it demonstrated some agentic analysis behavior.
- This experiment is less a leaderboard and more a user manual: it tells me how to steer each tool when I want real analysis instead of just a pretty code dump. For example, I can:
- Give Claude Code additional MCP tools to make it more adaptive for notebook analysis
- Ask Codex to inspect data before planning and do more on visualization and documentation
- Ask all tools to search the internet for appropriate content analysis methods.
Limitations of This Little Experiment
This experiment is not definitive, as it was limited to a single run per tool and each tool’s first plan. Results might differ if I ran multiple trials per tool and allowed several refinements of the plan.
Bonus Glitch In The Matrix
The top two startup ideas from Opus 4.1 were exactly the same as my previous project, which is impressive despite its tendency to jump to conclusions. Either it independently rediscovered my idea or I’ve been thinking a bit like a language model.