测评代码生成工具的自主数据分析能力
TL;DR(太长不看版):我让 Claude Code、Codex 和 Gemini 单独去啃一份微信群聊数据,看看它们的自主数据分析能力。Codex 的整体自主分析能力比较强,Claude Code 统计分析和可视化比较强,Gemini 表现不太行,所有工具在中文文本分析上都比较一般。
想看看代码工具能不能自主数分
这两年代码生成工具一路从“自动补全”长成了“订阅制实习生”,我就想看看它们的自主数据分析能力(agentic analytics)到底怎么样。我用相同的数据分析任务测试了三款代码生成工具:Claude Code(Opus 4.1 与 Sonnet 4.5)、Codex CLI(GPT-5-Codex)以及 Gemini CLI(Gemini 2.5 Pro)。
简单实验:数据集和提示词
数据: 一份包含 97,271 条微信群聊记录的数据集(已清洗、预处理和匿名化),时间跨度为2025年5月至9月,覆盖 16 个群,1,688 名用户。
初始提示词:
“我有一份中文微信群聊数据 @data.parquet。请在 jupyter notebook 分析数据并提炼见解。之后我们将基于这些见解构思产品思路,目前只是想先弄清大家讨论的内容、关注焦点以及其他相关信息即可。见解需完全从数据中深度挖掘,不得加入任何假设。请先制定分析计划。”
并批准它们生成的第一个计划。
后续提示词 (必要时使用):
“你是一名专业的数据分析师,请自行运行 notebook:1)修复所有报错;2)根据运行结果优化分析过程。“
各选手现场表现
虽然在这一简单设置下,所有工具都没能分析出什么有用的结果,但它们在分析方法上的差异比较有意思。
1. Claude Code:Opus 4.1,Ultrathink
过程: Opus 先看了数据两次(一次看列名和数据量,一次跑统计信息),然后制定分析计划。一次性生成整个 notebook 的分析代码,然后尝试运行,但因缺少 nbconvert 包跑不起来,就算任务完成了。notebook 我手动跑起来没问题,所以不需要后续提示词。Opus 是唯一第一次生成的 notebook 就能跑通的。
优势:
- 规划阶段很 agentic
- 代码注释完整
- 数据可视化很丰富
- 探索性数据分析(EDA)能力较强
劣势:
- 一口气生成代码无迭代
- 文本分析几乎基于片面的语言假设
- 急于得到最终结论,用了很多未经验证的假设
- 遗漏了计划中的部分分析步骤
- 直接用完了一个5小时限制
2. Claude Code:Sonnet 4.5,Ultrathink
过程: 与 Opus 4.1 几乎一样,但notebook有格式问题,所以用了后续提示词。
优势:
- 与 Opus 4.1 相似的优势,此外还包括:
- 严格按照计划一步步进行
- 文本分析更丰富
劣势:
- 与 Opus 4.1 版本的劣势基本相同(无步骤遗漏问题),此外还包括:
- 第二个提示词后依旧没有迭代分析
3. Codex CLI:GPT-5-Codex,High
过程: 先制定粗略计划,再看数据(列名和样本),生成的第一版 notebook 只有基础的数据处理流程与占位符。第二个提示词后,通过迭代方式修复代码问题、优化数据清洗与分析过程,还会根据执行结果调整分析计划。这里要夸一夸 Code:当发现无法直接运行 notebook 时,它会任劳任怨把每个代码块拉到命令行里过一轮单测,再把通过的版本写回 notebook。
优势:
- 第二个提示词后展现出较强的自主数据分析能力,根据分析结果迭代优化分析过程
- 中文理解能力不错,只有它知道 cpdd 什么意思
劣势:
- 数据可视化比较基础
- 完全没有代码注释
- 探索性数据分析比较弱,所以默认所有消息来自同一个群
4. Gemini CLI:Gemini 2.5 Pro
过程: 先制定计划,一点不看数据直接生成的第一版 notebook,只有最基本的数据处理,全是占位符。用了10+后续提示词来修复问题(字体、依赖包、格式等),还要引导它回到最初的分析计划。真是最难带的选手 🤦♂️
优势:
- 后续提示词下展现了些许自主数据分析能力,比如文本分析时再查看结果后优化停用词列表和数据清洗过程
劣势:
- 分析类代码能力较弱
- 虽会调整计划,但会遗漏部分步骤
- 对数据/中文理解能力较弱, 比如错误的认为数据来自一个游戏聊天群
- 需要最多的人工干预
可视化能力差异挺大




分析计划凸显风格
4个工具的分析计划结构相似,都是数据清洗/预处理、带可视化的探索性数据分析与内容分析,再提炼结论。其中,Claude Code 的计划最详细,Codex 侧重于快速得到初步分析,Gemini 的分析计划则最基础。
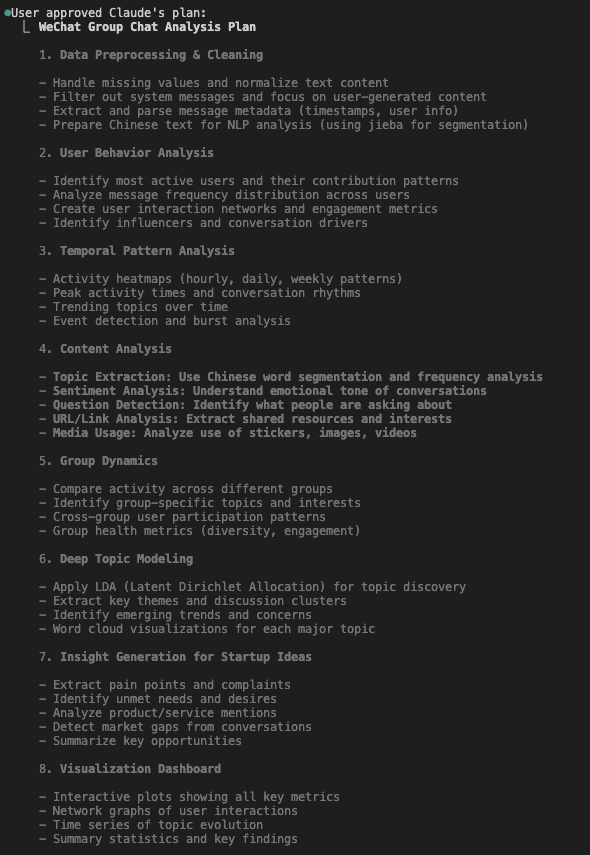
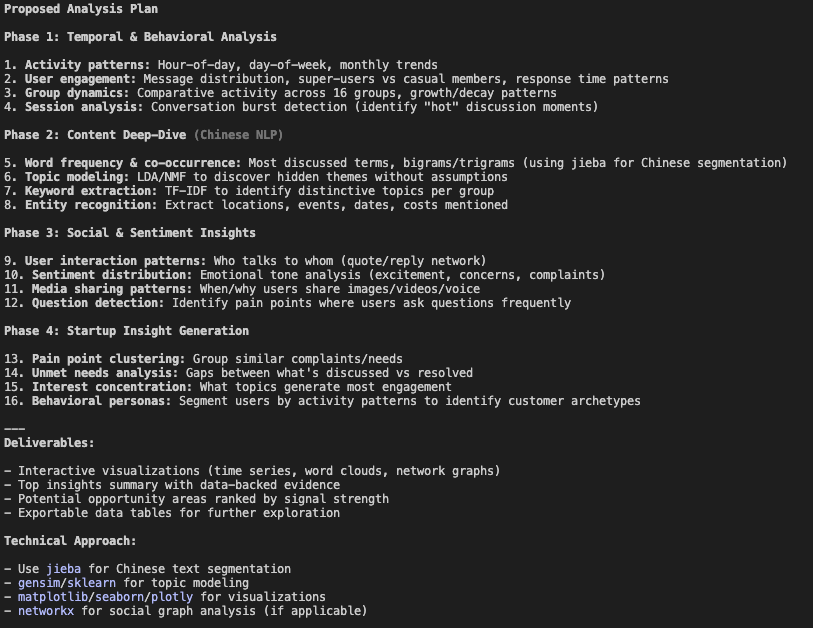
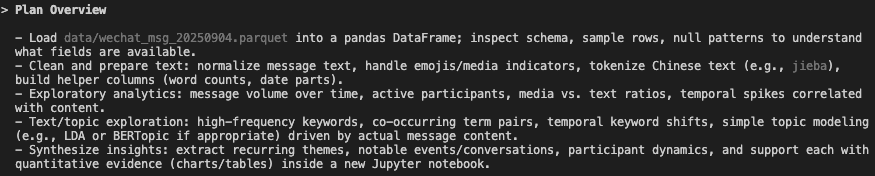
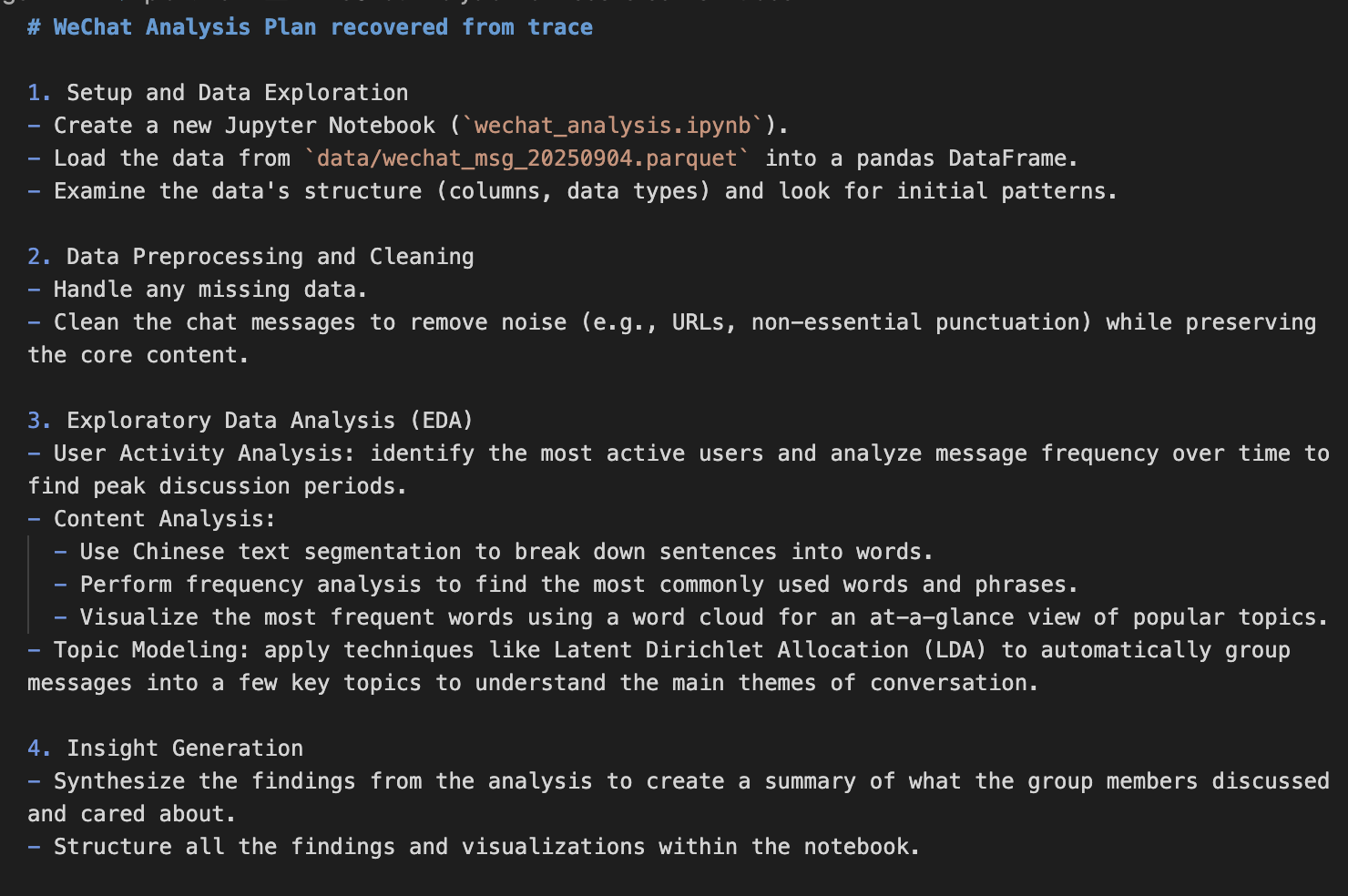
💡 Click on image to zoom in
还是得仔细打分
我从 7 个核心维度对各个工具进行评分,具体如下:
| 评估标准 | Claude Code Opus 4.1 | Claude Code Sonnet 4.5 | Codex GPT-5 | Gemini 2.5 Pro |
|---|---|---|---|---|
| 计划完整 | ||||
| 合理的任务拆解 | 1/1 | 1/1 | 1/1 | 1/1 |
| 各步骤的方法清晰,步骤间无逻辑断层 | 1/1 | 1/1 | 0.5/1 | 0.5/1 |
| 合理的深度和广度 | 1/1 | 1/1 | 0.5/1 | 0/1 |
| 方法严谨 | ||||
| 合理的分析方法选择 | 0.5/1 | 0.5/1 | 0.5/1 | 0/1 |
| 科学合理的执行 | 0/1 | 0/1 | 0.5/1 | 0/1 |
| 结果正确 | ||||
| 无错误且可复现 | 1/1 | 1/1 | 1/1 | 0/1 |
| 测试代码并自行修正 | 0/1 | 0/1 | 1/1 | 0/1 |
| 可视化效果 | ||||
| 合理且高质量的图表 | 1/1 | 1/1 | 0.5/1 | 0/1 |
| 沟通表达 | ||||
| 完善的文档说明 | 1/1 | 1/1 | 0/1 | 1/1 |
| 结论有数据支撑 | 0.5/1 | 0.5/1 | 1/1 | 0/1 |
| 指令遵循 | ||||
| 遵循计划 | 0.5/1 | 1/1 | 1/1 | 0/1 |
| 遵循指令 | 0.5/1 | 0.5/1 | 1/1 | 0.5/1 |
| 自主数据分析能力 | ||||
| 根据分析结果调整计划 | 0/1 | 0/1 | 1/1 | 0.5/1 |
| 迭代优化分析 | 0/1 | 0/1 | 1/1 | 0.5/1 |
| 自适应问题解决 | 0.5/1 | 0.5/1 | 1/1 | 0/1 |
| Total Score | 8.5/15 | 9/15 | 11.5/15 | 4/15 |
从评分结果可见:Codex 在自主数据分析能力上表现最优;Claude 在统计分析与可视化方面领先;Gemini 整体表现落后。所有工具在当前简单设定下中文文本分析能力都比较基础。
折腾完的收获
核心发现
- 数据优先 vs 计划优先。Claude Code 采用数据优先的方式,先看数据再定计划;Codex 与 Gemini 则采用计划优先的方式。数据优先在初步阶段效果更好,但我觉得只要工具有足够的自主数据分析能力,两种方式的差异影响并不大。
- 实验结果印证了各模型的典型特性:Claude Code 整体编码能力略优,喜欢呈现专业、商务化的结果,但存在急于得出结论、轻易放弃的问题;Codex 风格简洁,适应性强,执行任务的效率较高;Gemini CLI 仍有较大提升空间,但实际能力比表现出来的结果要好,翻看它的执行记录日志才发现它有自主数据分析能力。
- 这次测试更像是在摸清怎么给它们交代任务,而不是选出一个最好的工具。例如,我可以:
- 给 Claude Code 连接更多 MCP 工具来提升它与notebook的交互能力;
- 要求 Codex 先看数据再计划,增加EDA、可视化和代码注释;
- 让所有工具先网上搜索适合的分析方法。
实验局限
每个工具只进了一次测试。如果增加每个工具的测试次数,以及让它们先优化几次计划,测试结果可能会有所不同。
最后插曲
尽管 Opus 4.1 急于下结论、逻辑上有几次跳跃,但它给出的前两个产品方向拼在一起,其实非常接近我之前做的项目。那么问题来了,是 Opus 够聪明,还是我之前想的太简单?